
Apache Kafka

I'm Venkata Pavan Vishnu, a cloud enthusiast with a strong passion for sharing knowledge and exploring the latest in cloud technology. With 3 years of hands-on experience in AWS Cloud, I specialize in leveraging cloud services to deliver practical solutions and insights for real-world scenarios. Whether it's through engaging content, cloud security best practices, or deep dives into storage solutions, I'm dedicated to helping others succeed in the ever-evolving world of cloud computing. Let's connect and explore the cloud together!
Kafka was originally developed by LinkedIn, In 2011, it became an open-source project mainly maintained by confluent, IBM, and Cloudera.
Jay Kreps seems named it after the author Franz Kafka because it is “a system optimized for writing”, and he liked Kafka’s work.
Why Kafka?
Apache Kafka is a well-known name in the world of Big Data. It is one of the most used distributed streaming platforms.
Let us make this understood in a scenario of challenges faced by a company during data integration:
So the company will have a source system for example Database. Now, where another part of the company wants to take that data and put it into another system like the Target system. We can just simply write a code to take the data, extract it, and then transform it.
As the company evolves after some time there will be more source systems and target systems. Now, the data integration part will be more complicated and challenging because all of your source systems need to send data to all your target systems.
Let us consider there are 5 source systems and 8 target systems, now you need to take care of about 40 integrations. Every integration comes with difficulties like Data Format, Data schema, and each source system will have an increased load from the connections.
Now Kafka comes into the picture by decoupling the systems and data streams.
The source system acts as a producer that sends data to Kafka ( all the data from the source system will store here ) any time any target system needs data it can just consume it from apache kafka.
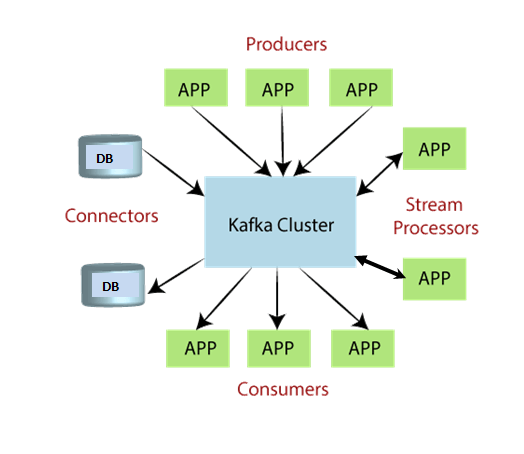
What is Kafka?
Kafka is Distributed, resilient architecture, and fault tolerant. It is horizontally scalable, we can scale up to 100s of brokers and huge scale for message throughputs like millions of messages per second.
It was used by 2000+ firms,80% of the Fortune 100 like LinkedIn, Airbnb, Uber, Netflix, Lyft, Tesla, Twitter, and many others.
For example:
Uber and Lyft use Kafka to gather trip data in real-time to compute and forecast the demand.
Netflix uses Kafka for recommendations in real-time while you're watching shows.
Tesla uses event streaming architecture for autonomous vehicle development, supply chain optimization, and manufacturing.
Use Cases of Kafka
Messaging System (pub-sub model),
Activity Tracking,
Application logs gathering,
Stream processing,
Gathering metrics from various locations,
De-coupling of system dependencies,
Integration with Big Data Technologies like Flink, Spark, and Hadoop.
and many more..........
Kafka Terminologies
Kafka only accepts the bytes as input from producers and sends bytes ut as output to consumers. Internally, it uses Message Serializer at the producer end and a Message deserializer at the consumer end
Kafka Topics
It is a particular stream of data within your Kafka cluster. It is similar to a table in a database without all constraints because you can send anything to a Kafka topic. It is immutable. Data can be kept for a limited time(default is one week)
You can have as many topics as you want. Typically a topic is identified by its name in the Kafka cluster. These Kafka topics can support any kind of message format like JSON, Avro, text file, binary, and whatever you want. The sequence of the messages is called a data stream which we saw earlier scenario.
There is no querying capability for Kafka topics, instead, use the Kafka producers send the data, and the Kafka consumer reads the data.
Partitions
The Kafka Topics are split into partitions. for example, a topic can be made of 200 partitions. When we send a message in Kafka topic will be ended in a partition and messages within the partition are ordered(order is not guaranteed across partitions).
The partition can receive messages from one or more producers. Until you define a Message key, data is assigned to partitions randomly.
Offset
Each message in the partition will get an incremental id is called an offset. offset is cant be retained even after the previous message is deleted.
Kafka Producers
The producer ingests/sends the data to the topics. It knows in advance which partition they need to write and which broker and server have it. It will recover automatically when there is a Kafka broker failure. By sending a Message Key together with data we can assure that data is written into the particular partition.
if the key is null, data is going to be sent round-robin like partition 0, then partition 1.
if the key is not null, then all messages for that key are sent always to the same partition. Internally it implements some key hashing technique(murmur2 algorithm) and maps the key to a partition
Kafka Consumers
After the producer sends data to the topics we need to pull them and consume them using Kafka Consumer.
Consumers can read data from more than one partition in a topic. In a similar fashion to how the producer recovers when the broker fails, the Consumer knows how to recover too. Data that is read will be in order from low offset to high offset within each partition.
Kafka Brokers
A Kafka cluster is an ensemble of multiple Kafka brokers. A Kafka broker is nothing but a server that contains a topic partitions. Each broker is identified by its ID(ID must be an integer. Every Kafka broker is also called a Bootstrap Server
Zookeeper
Zookeeper simply manages the information regarding the Kafka Brokers. Whenever the broker is going down. The Zoo keeper will perform the Leader election for the partitions. It will notify whenever a new topic is created or deleted in the broker. It operates with an odd number of servers (1,3,5,7)
Now Zookeeper has been replaced with Kafka Kraft due to scaling issues and other performance factors like stability, security, recovery time, etc.
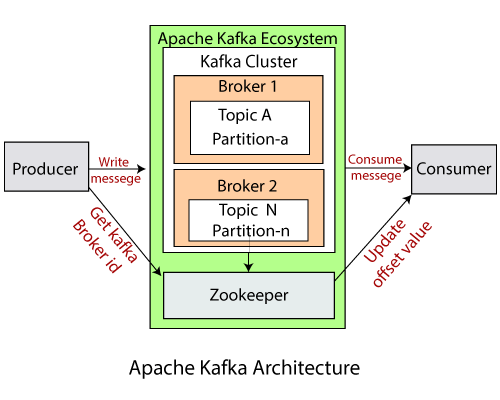
This is all about Apache Kafka in a general overview.




